开局来几个测试:(网页在线编译器和本地编译器结果可能会不太一样)
// 测试1
float a = 20000000.0f;
float b = 1.0f;
float sum = a + b;
Console.WriteLine(sum);
// 测试2
float sum = 0f;
for (int i = 0; i < 20000000; i++)
sum += 1.0f;
Console.WriteLine(sum);
// 测试234567....
float v = 0.1f;
float v1 = 1.0f;
float v2 = 0.8f;
Console.WriteLine(0.2);
Console.WriteLine("v+v+v-v ={0}", v + v + v - v);
Console.WriteLine(".1f+.1f+.1f-.1f={0}", .1f + .1f + .1f - .1f);
Console.WriteLine("v1 - v2 ={0}", v1 - v2);
Console.WriteLine("1.0f - .8f ={0}", 1.0f - 0.8f);
Console.WriteLine("1.2f - 1f ={0}", 1.2f - 1f);
Console.WriteLine("2.2f - 2f ={0}", 2.2f - 2f);
Console.WriteLine("3.2f - 3f ={0}", 3.2f - 3f);
Console.WriteLine("4.2f - 4f ={0}", 4.2f - 4f);
Console.WriteLine("5.2f - 5f ={0}", 5.2f - 5f);
Console.WriteLine("6.2f - 6f ={0}", 6.2f - 6f);
Console.WriteLine("7.2f - 7f ={0}", 7.2f - 7f);
Console.WriteLine("8.2f - 8f ={0}", 8.2f - 8f);
Console.WriteLine("9.2f - 9f ={0}", 9.2f - 9f);
浮点数问题
上述测试本地运行输出如下:
20000000
16777216
0.2
v+v+v-v =0.20000002
.1f+.1f+.1f-.1f=0.20000002
v1 - v2 =0.19999999
1.0f - .8f =0.19999999
1.2f - 1f =0.20000005
2.2f - 2f =0.20000005
3.2f - 3f =0.20000005
4.2f - 4f =0.19999981
5.2f - 5f =0.19999981
6.2f - 6f =0.19999981
7.2f - 7f =0.19999981
8.2f - 8f =0.19999981
9.2f - 9f =0.19999981
1-0.8得到的是一个0.19999999,虽然这不符合数学逻辑,但是浮点数存储在二进制里,它只能做到这一步。如果放大10倍再用int转型,会出现1或2的差异。
在计算机中,整数用小数点在最末位数后的定点数来表示。
计算机二进制小数
和整数的二进制表示采用“除以 2,然后看余数”的方式相比,小数部分转换成二进制是用一个相似的反方向操作,就是乘以 2,然后看看是否超过 1。如果超过 1,我们就记下 1,并把结果减去 1,进一步循环操作。在这里,我们就会看到,0.1 其实变成了一个无限循环的二进制小数,0.000110011。这里的“0011”会无限循环下去。

浮点数的表现形式:
±m*ne
±符号 .m尾数.n基数.e指数
计算机内部使用的是二进制表示,因此n是2,实际中只考虑±,m,e就可以表示浮点数。
浮点数形式:

IEEE规定浮点数的内部构造
单精度浮点数:符号(1位)指数(8位)尾数(23位)
双精度浮点数:符号(1位)指数(11位)尾数(52位)
定点数形式:
123.45
0.012345
二进制小数转换为十进制小数

二进制对于小数有误差的原因

2的多少次幂怎么相加都不会得到0.1这个结果,实际上0.1转换为二进制后会变成0.00011001100…(1100无限循环),就像无法用十进制表示⅓一样,0.3333…计算机遇到无限循环小数时会从中间截断或者四舍五入,会成为0.333,3 * 0.333 ≠ 3 * ⅓ 误差就是这样产生的。
尾数
正则表达式可以将表现形式多样的浮点数统一为一种形式
例如: 十进制0.75不同的表现形式:
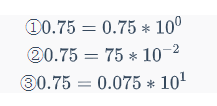
计算机处理会比较麻烦,因此需要统一的规则,比如可以制定小数点前面是0,后面的第一位不能是0这种规则,根据这个规则0.75就只有 ①这种表示形式。根据规则来表达的方式就是正则表达式。
在二进制中,使用 将小数点前面的值固定为1的正则表达式。
将二进制表示的小数左移或右移数次(逻辑移位,符号位是独立的),整数部分的第一位变成1,第二位之后变成0
例如:
// 原始数值
1011.0011
// 右移使整数部分第一位为1其余为0
0001.0110011
// 使小数点后为23位(单精度位数有23位精度)
0001.0110 0110 0000 0000 0000 000
// 仅保留小数点后面的部分,完成正则表达式
0110 0110 0000 0000 0000 000
// 因为小数点左边第一位固定是1被省略了,所以实际是24位
指数
主要是为了在指数部分表示负数时不使用符号位
Excess系统表现是指:通过将指数部分表示范围的中间值设为0,使得负数不需要使用符号来表示。
单精度浮点数指数部分(8位),最大值为1111 1111=255, 它的½即为0111 1111=127(右移小数部分舍弃) 来表示0。

双精度浮点数指数部分(11位),最大值为111 1111 1111=2047, 它的½即为011 1111 1111=1023(右移小数部分舍弃) 来表示0。
用1 ~ 13 来表示负数,可以把中间的7当成0, 因此10就是+3,3就是-4。这个规则就是Excess系统。
代码验证
public static void Print(float data)
{
byte[] b = BitConverter.GetBytes(data);
var str = Convert.ToString(b[3], 2).PadLeft(8, '0') +
Convert.ToString(b[2], 2).PadLeft(8, '0') +
Convert.ToString(b[1], 2).PadLeft(8, '0') +
Convert.ToString(b[0], 2).PadLeft(8, '0');
var str1 = str.Substring(0, 1) + "-" +
str.Substring(1, 8) + "-" +
str.Substring(9, 23);
Log.Information("符号位(1位)-指数部分(8位)-尾数部分(23位)\n " +
"单精度:{data:0.000} {str1}\n", data, str1.Replace(" ", ""));
}
符号位(1位)-指数部分(8位)-尾数部分(23位)
单精度:0.750 0-01111110-10000000000000000000000
符号位(1位)-指数部分(8位)-尾数部分(23位)
单精度:0.100 0-01111011-10011001100110011001101
符号位(1位)-指数部分(8位)-尾数部分(23位)
单精度:0.750 0-01111110-10000000000000000000000
符号位:0 因为0.75是正数,所以符号为0
指数部分:01111110 = 126 用Excess系统表现就是-1(126-127=-1)
尾数部分:10000000000000000000000 根据正则表达式规则,小数点前一位是1,因此表示的是1.10000000000000000000000转换为十进制

0-01111110-10000000000000000000000 表示的就是:
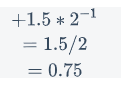

来算一下0.1的二进制转换成十进制的值:
符号:0 为正
指数:123-127=-4
尾数:(分数计算器)

可以看到并不是等于0.1,出错的原因之一是采用浮点数来处理小数,也有因“位溢出”而造成计算错误的情况。

浮点数加法
搞清楚了怎么把一个十进制的数值,转化成 IEEE-754 标准下的浮点数表示,我们现在来看一看浮点数的加法是怎么进行的。其实原理也很简单,那就是先对齐、再计算。
两个浮点数的指数位可能是不一样的,所以我们要把两个的指数位,变成一样的,然后只去计算有效位的加法就好了。
比如 0.5,表示成浮点数,对应的指数位是 -1,尾数是 00…

0.125 表示成浮点数,对应的指数位是 -3,尾数也还是 00…

那我们在计算 0.5+0.125 的浮点数运算的时候,首先要把两个的指数位对齐,也就是把指数位都统一成两个其中较大的 -1。
对应的尾数也要对应右移两位,因为 尾数前面有一个默认的 1,所以就会变成 0.01。然后我们计算两者相加的有效位 1.f,就变成了有效位 1.01,而指数位是 -1,这样就得到了我们想要的加法后的结果。实现这样一个加法,也只需要位移。和整数加法类似的半加器和全加器的方法就能够实现,在电路层面,也并没有引入太多新的复杂性。
回到浮点数的加法过程,你会发现,其中指数位较小的数,需要在尾数进行右移,在右移的过程中,最右侧的尾数就被丢弃掉了。这会导致对应的指数位较小的数,在加法发生之前,就丢失精度。两个相加数的指数位差的越大,位移的位数越大,可能丢失的精度也就越大。当然,也有可能你的运气非常好,右移丢失的有效位都是 0。这种情况下,对应的加法虽然丢失了需要加的数字的精度,但是因为对应的值都是 0,实际的加法的数值结果不会有精度损失。
单精度浮点数的尾数有效位长度一共只有 23 位,如果两个数的指数位差出 23 位,较小的数右移 24 位之后,所有的有效位就都丢失了。这也就意味着,虽然浮点数可以表示上到 3.40×1038,下到 1.17×10−38 这样的数值范围。但是在实际计算的时候,只要两个数,差出 224,也就是差不多 1600 万倍,那这两个数相加之后,结果完全不会变化。
float a = 20000000.0f;
float b = 1.0f;
float sum = 0f;
Console.WriteLine(a+b); // 解释了这个为什么是20000000
// 用一个循环相加 2000 万个 1.0f,最终的结果会是 1600 万左右,而不是 2000 万。这是因为,加到 1600 万之后的加法因为精度丢失都没有了。这个代码比起上面的使用 2000 万来加 1.0 更具有现实意义
for (int i = 0; i < 20000000; i++)
sum += b;
Console.WriteLine(sum);// 16777216
64位浮点数(double),尾数有效位是52位,所以相差253 会丢失较小的数
如何避免问题
一般情况下,在实践应用中,对于需要精确数值的,比如银行存款、电商交易,我们都会使用定点数或者整数类型。
精度丢失问题
使用Kahan Summation 算法,也称补偿求和
那么,我们有没有什么办法来解决这个精度丢失问题呢?虽然我们在计算浮点数的时候,常常可以容忍一定的精度损失,但是像上面那样,如果我们连续加 2000 万个 1,2000 万的数值都会被精度损失丢掉了,就会影响我们的计算结果。一个常见的应用场景是,在一些“积少成多”的计算过程中,比如在机器学习中,我们经常要计算海量样本计算出来的梯度或者 loss,于是会出现几亿个浮点数的相加。每个浮点数可能都差不多大,但是随着累积值的越来越大,就会出现“大数吃小数”的情况。
面对这个问题,聪明的计算机科学家们也想出了具体的解决办法。他们发明了一种叫作Kahan Summation的算法来解决这个问题。
其实这个算法的原理其实并不复杂,就是在每次的计算过程中,都用一次减法,把当前加法计算中损失的精度记录下来,然后在后面的循环中,把这个精度损失放在要加的小数上,再做一次运算。
如果你对这个背后的数学原理特别感兴趣,可以去看一看Wikipedia 链接里面对应的数学证明,也可以生成一些数据试一试这个算法。这个方法在实际的数值计算中也是常用的,也是大量数据累加中,解决浮点数精度带来的“大数吃小数”问题的必备方案。
function KahanSum(input)
var sum = 0.0 // 累加变量
var c = 0.0 // 对丢失的低阶位的运行补偿。
for i = 1 to input.length do
var y = input[i] - c // c第一次是零。
var t = sum + y // 如果,sum总和大,y小,所以y的低位数字丢失了。
c = (t - sum) - y // (t-sum)抵消y的高阶部分; 减去y可得到负值(y的低部分)
sum = t // 代数上,c应该始终为零。 当心过于激进的优化编译器!
next i // 下次,丢失的低部分将被重新添加到y中。
return sum
/////////////////////////////////////////////////////////////////////////
float c = 0f;
b = 1.0f;
sum = 0f;
for (int i = 0; i < 20000000; i++)
{
float d = b - c;
float t = sum + d;
c = (t - sum) - d;
sum = t;
}
Console.WriteLine(sum); // 这次输出20000000
Kahan Summation算法实际上并不会完全精确,他只是每次把丢失的精度累计起来。比如:+1后的结果和原结果相同,说明丢失了,那么+1被累积;下次就会尝试+2,再不行+3,直到能加起来为止(很可能出现加多了的情况,这时候累计的值就为负数)。而这个过程中如果停止累积,就会有精度丢失。但这种丢失对整体而言是可以接受的。
定点数
强烈建议看一下此知乎文章:帧同步:浮点精度测试
- 代码中使用float的问题,我们通过在逻辑层使用定点数取代float来解决。我在刚入行的时候使用过定点数,当时主要是为了解决在手机上浮点数运算非常慢的问题。早期Doom,Quick等都使用过定点数的优化方式,在3D游戏编程大师的书中还提供过一套定点数学库。我的一个同事在此基础上实现了一套基于定点数的数学库,提供和Unity相似的接口,并对一些函数做了查表优化。另一个同事修改了导表工具,使得策划的填表数据也支持定点数,完美解决。后来我们还逆向了另外一款爆款帧同步游戏看了一下,他们也做了特殊处理,使用乘1000的方式来解决,类似我们的顶点数学库但更难使用。
- 因为大量使用了真实的3D物理,所以物理对我们来说是一道跨不过去的槛。我们尝试过多种解决方案,先是让公司引擎组的同事帮忙修改Unity和PhysX源码发现工作量巨大,然后又尝试修改bullet为定点数替换PhysX,但是修改后的Unity版本性能差了几百倍无法使用。最终迫于时间压力,我们还是采用了有些隐患的做法:只使用Unity最基本的射线和BoxCollider,在此基础上实现了一套简单的定点数物理引擎。但是即使这样还是会出现不一致的问题,我们又加入了尾数截断,按碰撞方向截断等方式保障一致性。最终在几十万把上线测试中还没有发现物理导致的不一致问题。(需要说明的是,如果要使用动态碰撞器,需要修改一下Unity源码,让物理引擎的Update可以再逻辑帧驱动,非常感谢引擎组同事的帮忙。Unity的新版好像提供了这个功能。)
- Navmesh没有发现问题,我们实际使用也没出现问题,我们只使用了Navmesh的路点。
小数转整数来计算
小数计算时可能会出错,但进行整数计算(只要不超过可处理的数值范围)就一定没问题。因此进行小数计算时可以暂时使用整数,然后再把结果用小数表示出来即可。
例如0.1相加100次这个计算,可以转换为0.1扩大10倍再相加100次,最后把结果除以10即可。
BCD(二进制化十进制数)
简单来讲,BCD就是用4位来表示09的1位数字的处理方法。常用于老式的大型计算机中,BCD分为Zone十进制数形式和Pack十进制数形式。在涉及财务计算等不允许出现误差的情况下,一定要使用小数转整数或者BCD方法以确保最终得到的是准确数值。
这种编码技巧最常用于会计系统的设计里,因为会计制度经常需要对很长的数字串作准确的计算。相对于一般的浮点式记数法,采用BCD码,既可保存数值的精确度,又可免去使电脑作浮点运算时所耗费的时间。此外,对于其他需要高精确度的计算,BCD编码亦很常用。
(日常所说的BCD码大都是指8421BCD码的形式。)
| 十进制 | 8421BCD编码 |
|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
8421BCD编码中1010 ~ 1111都是无效的
10对应的就是00010000
11对应的就是00010001
当两个BCD码相加,如果和等于或小于 1001(即十进制数9),不需要修正;如果相加之和在 1010 到1111(即十六进制数 0AH~0FH)之间,则需加 6 进行修正。

微软官方文档
Single值最多可有7个小数位数的精度,尽管它在内部维护最多9位数字。
看起来相等的两个浮点数在进行比较时可能不相等,因为其最小有效位不同。
如果使用的是十进制数,则使用浮点数的算术或比较运算可能不会产生相同的结果,因为二进制浮点数可能不等于十进制数。
根据数字类型以及是否存在精度说明符,常规(“G”)格式说明符将数字转换为更紧凑的定点表示法或科学记数法。 精度说明符定义可以出现在结果字符串中的最大有效位数。 如果精度说明符被省略或为零,则数字的类型决定默认精度,float默认为7位有效精度。
“G”或“g” 更紧凑的定点表示法或科学记数法。精度说明符:有效位数。默认值精度说明符:具体取决于数值类型。
往返(“ R”)格式说明符 : 确保将转换为字符串的数字值解析回相同的数字值。仅Single,Double和BigInteger类型支持此格式。对于双精度值,“R”格式说明符在某些情况下无法成功往返原始值。对于double和float,相对较差的性能。相反,我们建议您对双精度值使用“G17”格式说明符,对单精度值使用“G9”格式说明符。
若要将视为相等,两个 float 值必须表示相同的值。 不过,由于值之间的精度差异,或由于一个或两个值的精度损失,应相同的浮点值通常会因其最小有效位之间的差异而不相等。 因此,调用 Equals 方法来确定两个值是否相等,或调用 CompareTo 方法来确定两个值之间的关系 Single ,通常会产生意外结果。
建议比较的方式
- 调用
Math.Round 方法以确保这两个值具有相同的精度。
float value1 = .3333333f;
float value2 = 1.0f/3;
int precision = 7;
value1 = (float) Math.Round(value1, precision);
value2 = (float) Math.Round(value2, precision);
Console.WriteLine("{0:R} = {1:R}: {2}", value1, value2, value1.Equals(value2));
- 测试近似相等性,而不是相等。 此方法要求您定义一个绝对量,而这两个值可能会不同,但仍相等,或者您定义较小值与较大值之间的差异。
测试相等性时,有时将Single.Epsilon用作两个Single值之间距离的绝对度量。然而,Single.Epsilon衡量的是可以与零的单个相加或相减的最小可能值。对于大多数正值和负值,Single.Epsilon的值太小,检测不到。因此,除了零之外,我们不建议在相等测试中使用Epsilon。
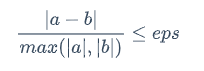
float one1 = -0.1f * 10;
float one2 = 0f;
for (int i = 0; i < 10; i++)
one2 -= 0.1f;
Console.WriteLine("{0} == {1} : {2}", one1, one2, one1.Equals(one2));
Console.WriteLine("{0} ≈ {1}: {2}", one1, one2,
IsApproximatelyEqual(one1, one2, 0.000001f)); // 7位精度
// -1 == -1.0000001 : False
// -1 ≈ -1.0000001: True
static bool IsApproximatelyEqual(float value1, float value2, float epsilon)
{
// 如果Equals判断相等则直接返回
if (value1.Equals(value2))
return true;
// 处理NaN(非数字),Infinity无穷。如果其中有NaN或者无穷,直接返回Equals结果
if (Double.IsInfinity(value1) | Double.IsNaN(value1))
return value1.Equals(value2);
if (Double.IsInfinity(value2) | Double.IsNaN(value2))
return value1.Equals(value2);
// 处理零以避免被零除
double divisor = Math.Max(Math.Abs(value1), Math.Abs(value2));
if (divisor.Equals(0))
divisor = Math.Min(Math.Abs(value1), Math.Abs(value2));
return Math.Abs(value1 - value2) / divisor <= epsilon;
}
异常和特殊情况
1.如果浮点运算的结果对于目标格式来说太小,当两个非常小的浮点数相乘时,可能会出现则结果为零。
public class Example
{
public static void Main()
{
float value1 = 1.163287e-36f;
float value2 = 9.164234e-25f;
float result = value1 * value2;
Console.WriteLine("{0} * {1} = {2}", value1, value2, result);
Console.WriteLine("{0} = 0: {1}", result, result.Equals(0.0f));
}
}
// 1.163287E-36 * 9.164234E-25 = 0
// 0 = 0: True
2.如果浮点运算结果的大小超出目标格式的范围,则操作的结果为 PositiveInfinity 或 NegativeInfinity (适用于结果的符号)
3.具有无效输入的任何浮点运算。 例如,如果尝试查找负值的平方根,则返回 NaN 。
相关资料
浮点数和定点数(下):深入理解浮点数到底有什么用?
组成原理|为什么计算机中0.3 + 0.6 等于 0.899999999…?
★帧同步之:定点数(fixedpoint num)原理、运算、实现
https://0.30000000000000004.com/
如何给女朋友解释为什么计算机中 0.2 + 0.1 不等于 0.3 ?
Introduction to CSAPP(五)定点数表示
★关于计算机存储浮点数、一次有趣的问题探索(0.1+0.2=0.3?)
★帧同步:浮点精度测试
★六:帧同步联机战斗(预测,快照,回滚)
定点数
https://www-inst.eecs.berkeley.edu//~cs61c/sp06/handout/fixedpt.html
定点数和浮点数比较
- 性能:定点数 > 浮点数
- 范围:定点数 < 浮点数,根据需要控制小数位
- 一致性:定点数不同平台运算结果一致,浮点数不同平台运算结果可能不同
浮点精度的问题在PC上就有跨平台的问题,因为语言编译器不同使用的寄存器和运算过程中的舍入方式不同。就会导致在不同平台下相同的float运算会出现不同的结果
定点数表示
定点数原理
- 使用整形数中的一部分bit位作为整数部分,剩下的作为小数部分
| 25 | 24 | 23 | 22 | 21 | 20 | 二进制小数点 | 2^-1^ | 2^-2^ | 2^-3^ |
|---|
| 0 | 1 | 1 | 0 | 1 | 0 | . | 1 | 0 | 0 |
= 1 * 24 + 1 * 23 + 1 * 21 + 1 * 2^-1^
=26.5
这里例子设定整数部分是5位,小数部分是3位,这种规定小数点固定位置的方式就是定点数。
在计算机中,整数用小数点在最末位数后的定点数来表示
TrueSync中的定点数实现
/// <summary>
/// 表示一个Q31.32定点数。(1位符号位,31位整型,32位小数)
/// </summary>
[Serializable]
public partial struct FP : IEquatable<FP>, IComparable<FP>
{
/// <summary>
/// 用64位long的前31位来表示整数,后32位表示小数
/// </summary>
[SerializeField]
public long _serializedValue;
/// <summary>
/// 小数点位置
/// </summary>
public const int FRACTIONAL_PLACES = 32;
// 用定点数表示以下值
public const long ONE = 1L << FRACTIONAL_PLACES; // 1
public const long TEN = 10L << FRACTIONAL_PLACES; // 10
public const long HALF = 1L << (FRACTIONAL_PLACES - 1); // 0.5
/// <summary>
/// 整数部分 00000000-00000000-00000000-00000011 小数部分 0010 0100-0011 1111-0110 1010-1000 1000
/// 1/2^3+1/2^6+1/2^11+1/2^12+1/2^13+1/2^14+1/2^15+1/2^16+1/2^18+1/2^19+1/2^21+1/2^23+1/2^25+1/2^29
/// =76016977/536870912
/// =0.1415926534682512
/// </summary>
public const long PI = 0x3243F6A88;
用PI来说明:
0x3243F6A88十六进制形式转化成二进制为:
00000000-00000000-00000000-00000011 00100100-0011 1111-0110 1010-1000 1000
因为这个FP定点数定义小数点在32位,因此,
- 整数部分是:
00000000-00000000-00000000-00000011等于十进制3。
- 小数部分是:
00100100-00111111-01101010-10001000
- 2^-3^+2^-6^+2^-11^+2^-12^+2^-13^+2^-14^+2^-15^+2^-16^+2^-18^+2^-19^+2^-21^+2^-23^+2^-25^+2^-29^= 76016977 / 536870912=0.1415926534682512
所以0x3243F6A88代表的就是3.1415926534682512
★六:帧同步联机战斗(预测,快照,回滚)
最佳的解决办法,是使用实现更加精确和严谨,并经过验证的定点数数学库,在c#上,有一个定点数的实现,Photon网络的早期版本,Truesync有一个很不错的定点数实现。
其中FP,就可以完全代替float,我们只需要将我们自己的逻辑部分,float等改造为FP,就可以轻松解决。并且,能够很好的和我们protobuf的序列化方式集成(注意代码中的Attribute,如下图),保证我们的配置文件,也是定点数的。
TSVector对应Vector3,只要基于FP,可以自己扩展自己的数据结构。(当然,如果用到了复杂的插件,并且不开源,那么对于定点数的改造,就会困难很多)
三角函数通过查表方式实现,保证了定点数的准确
我个人认为,这一套的实现,是优于简单的乘10000,除10000的方式。带来的坏处,可能就是计算性能略差一点点,但是我们大量测试下来,对计算性能的影响很小,应该是能胜任绝大部分项目的需求。
对于计算的不确定性,我们也有一些小的隐患,就是,我们用到了Physics.Raycast来检测地面和围墙,让人物可以上下坡,走楼梯等高低不平的路,也可以有形状不规则的墙。这里会获得一个浮点数的位置,可能会导致不确定性,这里,我们用了数值截断等方式,尽量规避,经过反复测试,没有出现过不一致。但是这种方式,毕竟在逻辑上,存在隐患,更好的方式,是实现一套基于定点数的raycast机制,我们人力有限,就没时间精力去做了。这块,有篇文章讲得更细致一些,大家可以参看 帧同步:浮点精度测试。
原码、反码和补码的定义和转换
对于一个数, 计算机要使用一定的编码方式进行存储。原码, 反码, 补码是机器存储一个具体数字的编码方式。
机器数
一个数在计算机中的二进制表示形式, 叫做这个数的机器数
机器数是带符号的,在计算机用一个数的最高位存放符号, 正数为0, 负数为1.
比如,十进制中的数 +3 ,计算机字长为8位,转换成二进制就是00000011。如果是 -3 ,就是 10000011 。那么,这里的 00000011 和 10000011 就是机器数。
真值
因为第一位是符号位,所以机器数的形式值就不等于真正的数值。例如上面的有符号数 10000011,其最高位1代表负,其真正数值是 -3 而不是形式值131(10000011转换成十进制等于131)。所以,为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
例:0000 0001的真值 = +000 0001 = +1,1000 0001的真值 = –000 0001 = –1
原码
原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。
[+1]原 = 0000 0001
[-1]原 = 1000 0001
第一位是符号位. 因为第一位是符号位, 所以8位二进制数的取值范围就是:
[1111 1111 , 0111 1111] 即 [-127 , 127]
反码
正数的反码是其本身。
负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
[+1] = [00000001]原 = [00000001]反
[-1] = [10000001]原 = [11111110]反
可见如果一个反码表示的是负数, 人脑无法直观的看出来它的数值. 通常要将其转换成原码再计算.
补码
正数的补码就是其本身
负数的补码是在其原码的基础上,符号位不变, 其余各位取反, 最后+1。(即在反码的基础上+1)
[+1] = [00000001]原 = [00000001]反 = [00000001]补
[-1] = [10000001]原 = [11111110]反 = [11111111]补
对于负数, 补码表示方式也是人脑无法直观看出其数值的. 通常也需要转换成原码在计算其数值。
使用源码、反码和补码的原因
对于负数, 因为人脑可以知道第一位是符号位,在计算的时候我们会根据符号位, 选择对真值区域的加减。但是对于计算机, 加减乘数已经是最基础的运算,要设计的尽量简单。计算机辨别"符号位"显然会让计算机的基础电路设计变得十分复杂! 于是人们想出了将符号位也参与运算的方法。我们知道, 根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有减法, 这样计算机运算的设计就更简单了。
于是人们开始探索 将符号位参与运算, 并且只保留加法的方法. 首先来看原码:
计算十进制的表达式: 1-1=0
1 - 1
= 1 + (-1)
= [00000001]原 + [10000001]原
= [10000010]原
= -2
如果用原码表示,让符号位也参与计算, 显然对于减法来说, 结果是不正确的。这也就是为何计算机内部不使用原码表示一个数。
为了解决原码做减法的问题, 出现了反码:
计算十进制的表达式: 1-1=0
1 - 1
= 1 + (-1)
= [0000 0001]原 + [1000 0001]原
= [0000 0001]反 + [1111 1110]反
= [1111 1111]反 = [1000 0000]原
= -0
发现用反码计算减法, 结果的真值部分是正确的。而唯一的问题其实就出现在"0″这个特殊的数值上。虽然人们理解上+0和-0是一样的, 但是0带符号是没有任何意义的。而且会有[0000 0000]原和[1000 0000]原两个编码表示0。
于是补码的出现, 解决了0的符号以及两个编码的问题:
1-1
= 1 + (-1)
= [0000 0001]原 + [1000 0001]原
= [0000 0001]补 + [1111 1111]补
= [0000 0000]补
= [0000 0000]原
这样0用[0000 0000]表示, 而以前出现问题的-0则不存在了。而且可以用[1000 0000]表示-128:
(-1) + (-127)
= [1000 0001]原 + [1111 1111]原
= [1111 1111]补 + [1000 0001]补
= [1000 0000]补
-1-127的结果应该是-128,在用补码运算的结果中, [1000 0000]补 就是-128。但是注意因为实际上是使用以前的-0的补码来表示-128, 所以-128并没有原码和反码表示。(对-128的补码表示[1000 0000]补算出来的原码是[0000 0000]原, 这是不正确的)
使用补码, 不仅仅修复了0的符号以及存在两个编码的问题, 而且还能够多表示一个最低数. 这就是为什么8位二进制,使用原码或反码表示的范围为[-127, +127], 而使用补码表示的范围为[-128, 127]。
为什么是-128到127(原理再深入)
将钟表想象成是一个1位的12进制数. 如果当前时间是6点, 我希望将时间设置成4点, 需要怎么做呢?我们可以:
往回拨2个小时: 6 - 2 = 4
往前拨10个小时: (6 + 10) mod 12 = 4
往前拨10+12=22个小时: (6+22) mod 12 =4
所以钟表往回拨(减法)的结果可以用往前拨(加法)替代!
现在的焦点就落在了如何用一个正数, 来替代一个负数. 上面的例子我们能感觉出来一些端倪, 发现一些规律. 但是数学是严谨的. 不能靠感觉.
官方术语:“模”是指一个计量系统的计数范围.如时钟、日历等.计算机也可以看成一个计量机器,它也有一个计量范围.只要有一个计量范围,即都存在一个“模”.“模”实质上是计量器产生“溢出”的量,它的值在计量器上表示不出来,计量器上只能表示出模的余数.
首先介绍一个数学中相关的概念: 同余
同余的概念: 两个整数a,b,若它们除以整数m所得的余数相等,则称a,b对于模m同余
记作 a ≡ b (mod m)读作 a 与 b 关于模 m 同余。
4 mod 12 = 4 , 16 mod 12 = 4 , 28 mod 12 = 4 所以4, 16, 28关于模 12 同余.
负数取余:
(-2) mod 12 = 12-2=10
(-4) mod 12 = 12-4 = 8
(-5) mod 12 = 12 - 5 = 7
再回到时钟的问题上:
回拨2小时 = 前拨10小时
回拨4小时 = 前拨8小时
回拨5小时= 前拨7小时
结合上面学到的同余的概念.实际上:
(-2) mod 12 = 10
10 mod 12 = 10
-2与10是同余的.
(-4) mod 12 = 8
8 mod 12 = 8
-4与8是同余的。距离成功越来越近了。 要实现用正数替代负数, 只需要运用同余数的两个定理:
“≡”是数论中表示同余的符号。即给定一个正整数n,如果两个整数a和b满足a-b能被n整除,即(a-b)modn=0,那么就称整数a与b对模n同余,记作a≡b(modn),同时可成立amodn=b。
如果a ≡ b (mod m),c ≡ d (mod m) 那么:
(1)a ± c ≡ b ± d (mod m)
(2)a * c ≡ b * d (mod m)
所以:
7 ≡ 7 (mod 12)
(-2) ≡ 10 (mod 12)
7 -2 ≡ 7 + 10 (mod 12)
现在我们为一个负数, 找到了它的正数同余数. 但是并不是7-2 = 7+10, 而是 7 -2 ≡ 7 + 10 (mod 12) , 即计算结果的余数相等。
接下来回到二进制的问题上, 看一下: 2-1=1的问题。
2-1=2+(-1)
= [0000 0010]原 + [1000 0001]原
= [0000 0010]反 + [1111 1110]反
先到这一步, -1的反码表示是1111 1110。 如果这里将[1111 1110]认为是原码, 则[1111 1110]原 = -126, 这里将符号位除去, 即认为是126。
(-1) mod 127 = 126
126 mod 127 = 126
(-1) ≡ 126 (mod 127)
2-1 ≡ 2+126 (mod 127)
2-1 与 2+126的余数结果是相同的! 而这个余数, 正式我们的期望的计算结果: 2-1=1
所以说一个数的反码, 实际上是这个数对于一个模的同余数. 而这个模并不是我们的二进制, 而是所能表示的最大值! 这就和钟表一样, 转了一圈后总能找到在可表示范围内的一个正确的数值!
而2+126很显然相当于钟表转过了一轮, 而因为符号位是参与计算的, 正好和溢出的最高位形成正确的运算结果。
既然反码可以将减法变成加法, 那么现在计算机使用的补码呢? 为什么在反码的基础上加1, 还能得到正确的结果?
2-1=2+(-1)
= [0000 0010]原 + [1000 0001]原
= [0000 0010]补 + [1111 1111]补
如果把[1111 1111]当成原码, 去除符号位, 则: [0111 1111]原 = 127
其实, 在反码的基础上+1, 只是相当于增加了模的值:
(-1) mod 128 = 127
127 mod 128 = 127
2-1 ≡ 2+127 (mod 128)
此时, 表盘相当于每128个刻度转一轮。所以用补码表示的运算结果最小值和最大值应该是[-128, 128]。但是由于0的特殊情况, 没有办法表示128, 所以补码的取值范围是[-128, 127]。